CSV 파일을 DB에 import 후 AUTO_INCREMENT 초기화 및 재정렬 하기
데이터베이스는 완전 잘 모르지만, DB를 핸들링 하면서 테스트를 해봐야할 일이 생겼습니다. 예전에는 DB를 직접 생성하거나 액세스 할 일도 없었지만, 뭐 닥치면 다 해보는 거죠.
일단 테스트 환경이니, DB라고 겁 먹지 않고, 엑셀 같은 거 이려니~ 생각하도 요모조모 살펴보기로 합니다.
My-SQL 사용을 편리하게 - HeidiSQL
사실은 Maria-DB에서 프론트로 HeidiSQL을 이리저리 돌려보면서, DB라는 것을 알아가보고 있습니다.
DB에 대한 개념은 조금 알고 있는 정도고, 학교 다니던 소싯적 경영학 과목 시간에 SQL구문을 잠시 살펴봤던 정도 밖에 지식이 없습니다.
기업체를 주로 상대하는 B2B IT 분야를 오래 경험했지만, My-SQL류 DB들을 접해볼 기회도 거의 없었던 것 같습니다.
반면에, MS-SQL의 경우에는 개발자들이 다루는 것을 많이 보아오긴 했습니다.
아무튼 이번 포스팅에서는 My-SQL DB 테이블에 Excel로 작성된 데이터(정확하게는 CSV 파일로 구성된 데이터)를 밀어 넣는 실습입니다.
HeidiSQL로 DB를 시각적으로 접근
HeidiSQL이라는 프론트 툴을 사용하게 되면, DB를 시각화해서 볼 수 있어서 참 좋은 것 같습니다.
우선은 late_roomsinfo 테이블 생성해서 가지고 놀다, 테스트 데이터를 모두 삭제한 상태입니다.

CSV 데이터를 테이블에 밀어 넣기
엑셀로 만든 CSV 파일의 데이터를 late_roomsinfo 테이블에 밀어 넣어보려고 합니다.
각 호텔에 딸린 방들을 기록하는 테이블인데, 첫 행은 열의 이름을 주었습니다.

마지막 행은 908행. 첫 행을 제외하고 907개의 데이터가 들어 있는 셈입니다. 26개 호텔에서 보유하고 있는 객실이 총 907개인 셈이죠. 이걸 한번에 DB 테이블에 넣을 수 있다면 참 편하지 않을까? 하는 생각을 해보게 되었습니다.
HeidiSQL > 도구 > CSV 파일 가져오기...
HeidiSQL에서는 CSV 파일 가져오기라는 기능을 제공합니다. 완전 개꿀~

파일명: 에서 CSV 파일을 불러오도록 합니다.
파일 경로에 한글이 있으니 불려지지 않길래, 경로에 한글이 들어가지 않도록 하기 위해 D드라이브 아래에 temp 폴더를 만들고, 엑셀CSV 파일 또한 파일명에 한글이 없도록 해주었습니다.

인코딩은 UTF-8로 변경해주었고, 불러들일 때 첫 칼럼은 컬럼 명이니 무시하도록 합니다.
필드 종결자? 줄 종결자?
필드 종결자와, 줄 종결자라는 이름이 참 독특하게 느껴지는데, CSV 파일이 콤마(,)로 구분되어 있으므로 콤마(,)를 선택해줍니다. 줄 종결자는 \r\n을 선택해줬는데, 이 정보는 CSV 파일을 메모장에 불러와보면 쉽게 알 수 있습니다.
아무튼 '종결자'는 종결, 즉 이곳이 끝다~ 라고 알려주는 녀석인 것이죠.
Javascript의 경우에는 코드 행이 끝나면 ';(세미콜론)'을 종결자로 찍어주잖아요?

메모장에서 열어보면, 데이터는 콤마(,)로 구분되어 있고, Windows 환경에서 CRLF는 행종결자가 \r\n에 해당합니다. 인코딩은 UTF-8. 대충 한번 훑어보면면 쉽게 구분할 수 있겠습니다.
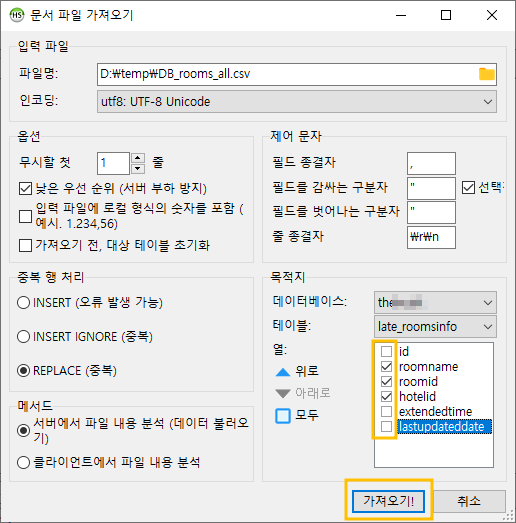
목적지는 대상을 말하는데, 데이터를 밀어 넣기 위한 데이터베이스와 테이블을 선택해주도록 합니다.
체크박스를 해제해줌으로써, CSV 파일의 열 갯수와 서로 맞춰주도록 한다.
그렇지 않으면 에러가 발생합니다.
이후 모든 설정세팅을 확인하고 나면 [가져오기!] 버튼을 클릭해주도록 합니다.

SQL 구문을 보니 뭔가실행이 되었는데 0.079초 만에 데이터를 import 했다고 표시된다. 그런데.. 1, 719 행이라고?
뭔가 오류가 있는듯 싶습니다.
아무튼, 쿼리를 날려보니, 데이터가 들어간 것 같기는 한데, 데이터를 썼다 지웠다를 반복했더니 id 값이 뒤죽박죽 되었습니다.
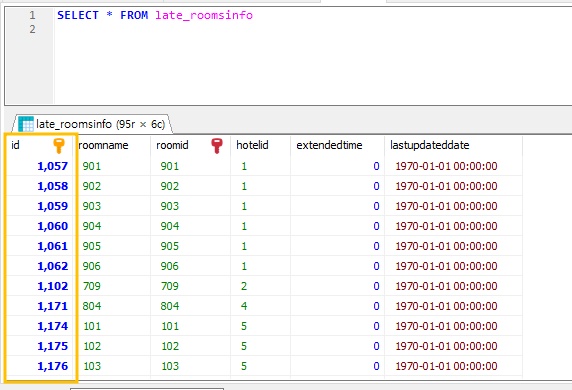
보기 좋게 1부터 시작하게 만드려고 하는 것이 이번 과제입니다.
AUTO_INCREMENT를 초기화 하기
특정값으로 시작하게 초기화 하려면, 아래와 같은 형태의 SQL 구문을 사용하게 됩니다.
ALTER TABLE `table_name` AUTO_INCREMENT = value;
위 구문을 참고하여, late_roomsinfo 테이블에 적용하려면, 다음과 같겠죠?
ALTER TABLE `late_roomsinfo` AUTO_INCREMENT = 1;
하지만, 테이블에는 이미 1보다 큰 값이 존재하기 때문에 변경되지 않습니다.
이 경우에는 AUTO_INCREMENT 값을 초기화 하고, 해당 테이블 안의 모든 데이터의 AUTO_INCREMENT 열의 값을 재조정해줘야 합니다.
ALTER TABLE `table_name` AUTO_INCREMENT=1;
SET @COUNT = 0;
UPDATE `table_name` SET auto_increment_column_name = @COUNT:=@COUNT+1;
학습을 위해 한번 더 써보도록 하죠,
ALTER TABLE `late_roomsinfo` AUTO_INCREMENT = 1;
SET @COUNT = 0;
UPDATE `late_roomsinfo` SET id = @COUNT:=@COUNT+1;
라고 쿼리를 작성해주고 실행을 위해 F9키를 눌러줍니다.

조건절(WHERE)이 없으므로, 테이블 전체에 적용이 되기 때문에 위험하다고 팝업이 나옵니다.
DB 공부를 이제 막 시작하는 참이라, 잠시 쫄보가 되었지만, 뭐.. 아무것도 안 들어 있는 DB인데 망하면 어떠리~
상남자답게 [ 예(Y) ] 버튼을 빡!!! 눌러줍니다.
아마도, DB를 업데이트 치는 ALTER라는 쿼리 명령어가 실행되기 때문에 WHERE 조건절이 없는 경우 안전하지 않다고 물어오는 것으로 보여집니다.
다시 조회를 위한 쿼리를 날려보면,
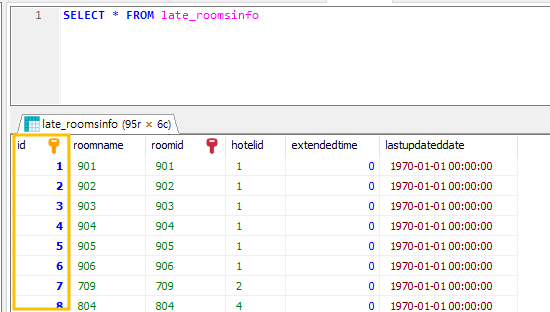
id 값이 1부터 잘 정리되어 나오는 것을 확인할 수 있습니다.
마치며
그런데, 말입니다.
사실은 이미 이 기능을 HeidiSQL은 제공하고 있습니다. 아래 문서 파일 가져오기 패널에서,
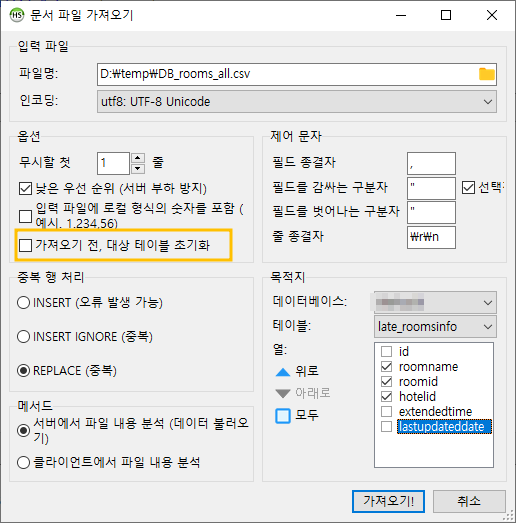
'가져오기 전, 대상 테이블 초기화' 옵션이 바로 그것입니다.
저 곳에 체크를 해주면, 복잡한 쿼리 없이도 알아서 1부터 시작하도록 다시 세팅을 해줍니다.
그래도, SQL 구문이 어떻게 이루어져 있는지 알고 사용을 하는 게 공부에 좋겠죠?
오늘도 즐거운 코딩생활, 즐코딩.
KINcoding.
'SQL(DB)' 카테고리의 다른 글
| SQL, 대소문자를 구분하고 싶을 때 (ft. 레코드 값 비교) - Binary (0) | 2023.09.25 |
|---|---|
| UTF-8과 UTF-8(BOM)의 차이는? (0) | 2023.08.22 |
| [HeidiSQL] 설치 및 한글 깨짐 현상 바로 잡기 (2) | 2023.07.04 |



댓글